Analyzing application of Q-Learning and Approximate Q-Learning in Python
To err is human- and so is to learn from the mistakes of the past. To think about the aftermaths of our past actions and to shape our future actions accordingly is a core part of our being human. Can machines do the same? And will that actually be a good idea? This is what the fascinating world of Reinforcement Learning explores.
Reinforcement Learning in Game Development
Works that Inspire Us
Applications of Artificial Intelligence and Machine learning in game development has shown fascinating results. The reason why Reinforcement Learning is specifically interesting is that it allows the agents to come up with unpredictable and mind-blowing techniques that can reach a new dimension of amazement level.
A game with deterministic environment often allows some room for exploitation. For example, the last cricket game by Electronics Arts, Cricket 07 allowed to take wicket in every ball by bowling in a particular area. Many speedrunners follow techniques like 'low-input speedrunning' to exploit the game.
But what if the non-playing agents were evolving with each playthrough? Trying to understand the good and the bad actions for the agent? Or what about just a fun game, but with a more lively ecosystem? Reinforcement Learning allows that.
The Issue of Realism in Games
Are games being too serious these days? Do we need more realism in games? These are good questions to we need to think of before we move on. Because already games like Red Dead Redemption II and many others has reached the level of insanity. Competitive gaming, e-sports and professional speedrunning are raising a question, aren't games supposed to be for fun?
Our take would be straightforward here- we do not think games need to be more realistic. Application of AI in game does not need to be only to make it harder and serious- but AI introduces new ways to make a game creative and engaging. The autonomous agents can behave as a game character should, but differently and intelligently in each runthrough making the game more interesting.
Pacman: Environments and Learning Parameters
The Pac-Man Projects - UC Berkeley CS188
A large portion of our work is based on 'The Pac-Man Projects’ from UC Berkeley CS188. This provided an environment with a modular design. Our project implemented Q-Learning and Approximate Q-Learning on that. We analyzed how the different parameters and higher training affects the performance in different layouts.
The Layouts
Pacman, as a game, needs no introduction. However, 'The Pac-man Projects' provide several layouts for the game. We have limited our work on 4 environment, that would need an introduction. We considered 2 things in deciding the layouts to work with. First, we wanted them to have distinguishable characteristics. Second, it had to be a smaller layout, as we had very limited computational power.
Small Grid: Very simple grid layoutSmall Classic: A smaller version of the classic PacmanOpen Classic: A open area with no walls within boundariesSmall Grid: A challenging layout, but with fewer possible states
States and Features
States (For Q-Learning)
Layout Information
Walls
Maze Width and Height
Food Information
Food dot locations
Power pellet locations
Agent Information
Pacman's position and direction
Ghost positions and directions
Ghost scared timer states
Whether agents are eaten
Game Information
Win/Loss state
Features Extraction (For Approximate Q-Learning)
Closest Food: Normalized distance to the closest food pellet.
Number of ghosts 1 step away
Food Eaten: 1 when agent eats food and no ghosts are nearby
Parameters Design (For Q-Learning)
We designed 4 sets of parameters for quick learning reflecting different human mindsets.
Agent Type
Learning Rate (α)
Discount Factor (γ)
Exploration Rate (ε)
Strategy Focus
Quick Learner
0.95
0.1
0.2
Adapt quickly to gain instant rewards
Explorer
0.7
0.5
0.5
Explore more learn more states
Conservative
0.5
0.6
0.1
Slow learning with long term priority
Strategist
0.6
0.8
0.3
Explore with long term priority
Application of Q-Learning
Q-Learning in Small Grid (5000 Training)
The grid being tiny, the agents reached towards optimized performance with Q-Learning after 5000 training. Only the explorer shows a failure of 28%, as it explored the more unlikely states as well in training.
Q-Learning in Small Classic (5000 Training)
A 0% success rate for all agents, suggesting for a little larger layout requires exponentially higher training.
Q-Learning in Open Classic (3000 Training)
Compared to other models, Open Classic required a higher amount of time and resource to simulate due to having so many possible states, and lower challenge. The results for the agents are even a greater disaster.
Q-Learning in Minimax
The most interesting results are from Minimax. Agents perform drastically different. They also show much improvement over training rewards vs actual performance.
Application of Approximate Q-Learning
Approximate Q-Learning in Small Grid
Approximate Q-Learning showed great perfor after just one training. With higher training it improved. But it quickly reached its limit and didn't improve further.
Approximate Q-Learning in Small Classic
This time it couldn't capitalize on one training. But just with 10 trainings, it reached a 88% winning rate, which also turned to be its limit.
Approximate Q-Learning in Open Classic
Interestingly, in the layout where Q-Learning models struggled the most, Approximate Q Learning shined at a 100% success with any number of training.
Approximate Q-Learning in Minimax
Turns to be interesting once again with ups and downs in its learning curve.
Findings and Analysis
Interestingly enough, we couldn't find any of the model to be generally better than another model. In fact, the shined in the exact opposite circumstances. Approximate Q-Learning did better in large open environments, where Q-Learning failed. And where Q-Learning shined, in grid environments, Approximate Q-Learning didn't perform as good.
Higher training always improves Q-Learning, but Approximate Q-Learning shows unstable performance. This is because it doesn't see all the states as distinct. It just extracts few features. Same feature set could mean different state and different best action. So it can get confused with training.
Take an example of a country boy who dwelled in a small town, never stepped into metropolitan cities. He has his own small place and own small dreams, his daily work-life is not pacey like city dwellers, this country boy works very slow but he tries to be accurate in his work, here the country boy is our Q-Learning agent. Q-L is best for small environments but very slow. It finds the best action for every possible state if given enough time which demands a lot of training session for better accuracy. Q-Learning benefits more from Quick Learner & Conservative styles because it needs time to converge on exact Q-values.
On the other hand, let’s have another story: A hot-headed, impulsive boy like a rich man's spoiled brat, hover over the city very fast with his dad's car, his mobility might be fast but he is a noob when it comes to drive, his reckless driving sometimes causes accidents, but he is the king of his own world, when his dad tries to teach him he cannot learn delicately and his performance goes way too bad like the same as Approximate Q-Learning. Approximate Q-L is faster but can be inconsistent. It works well in large environments and performance depends on feature selection—poor features lead to bad learning. Approximate Q-L benefits more from Explorer & Strategist styles since it focuses on feature-based learning and generalization.
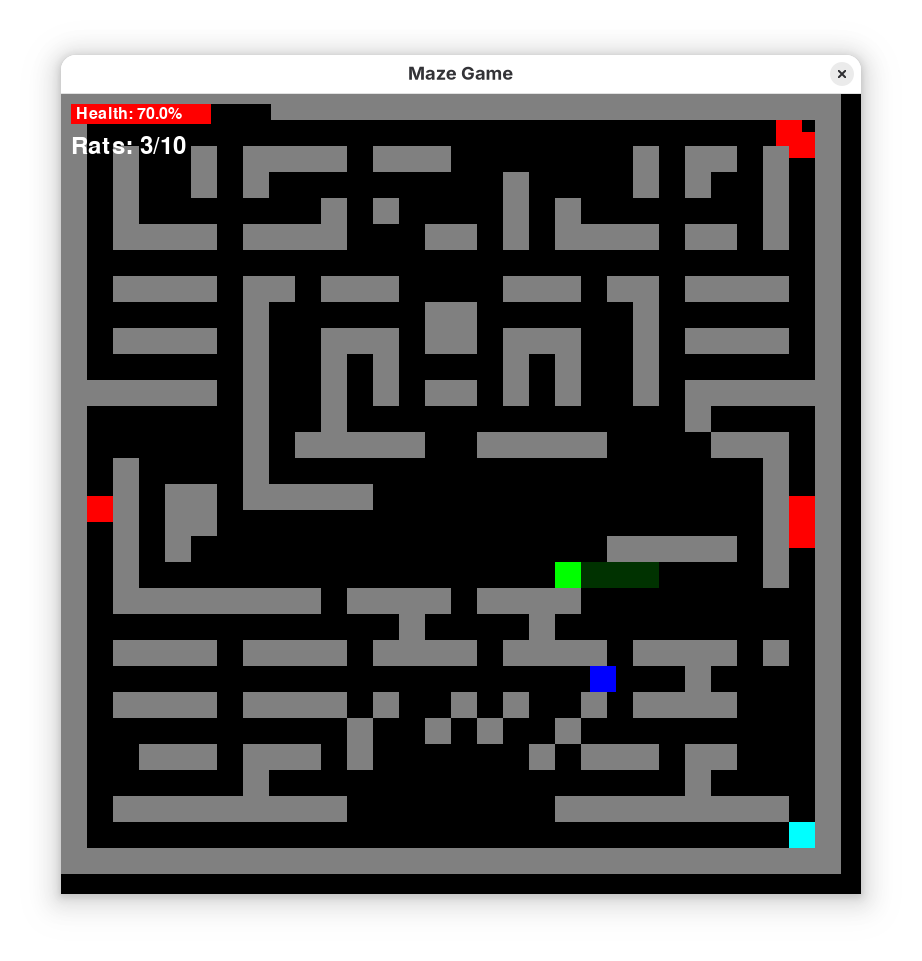
Application: The Simple Snake
There has been many research works and models based on RL. But interestingly, we do not see as many games intended primarily to be played to utilize this. This shows an issue of modern time, as much as we are invested in research and advancing knowledge and tech- we aren't that much Interested in utilizing what we already have. This is why we wanted to build a game as a part of the project. However, developing a full game is practically beyond our capability for now, so we made a simplifed version.
Possible Further Applications
The project was limited by time and resource constraints. So with more resources and more simulations, better analysis can be achieved. We focused on Q-Learning and Approximate Q Learning. There are policy learning and other forms of RL as well, which can be explored to understand the ways they can be applied.
But while further research can be worthwhile, applying the knowledge we have already gained may be even more compelling. The amazing aspect of Reinforcement Learning is the possibility of applications is endless. As we focused on game development, this is certainly a part where there's a great room for applications. Specially the way RL allows to design a dynamic world, can hardly be beat by other means. Our snake game is a basic and incomplete prototype for now, but we intend to develop it further.